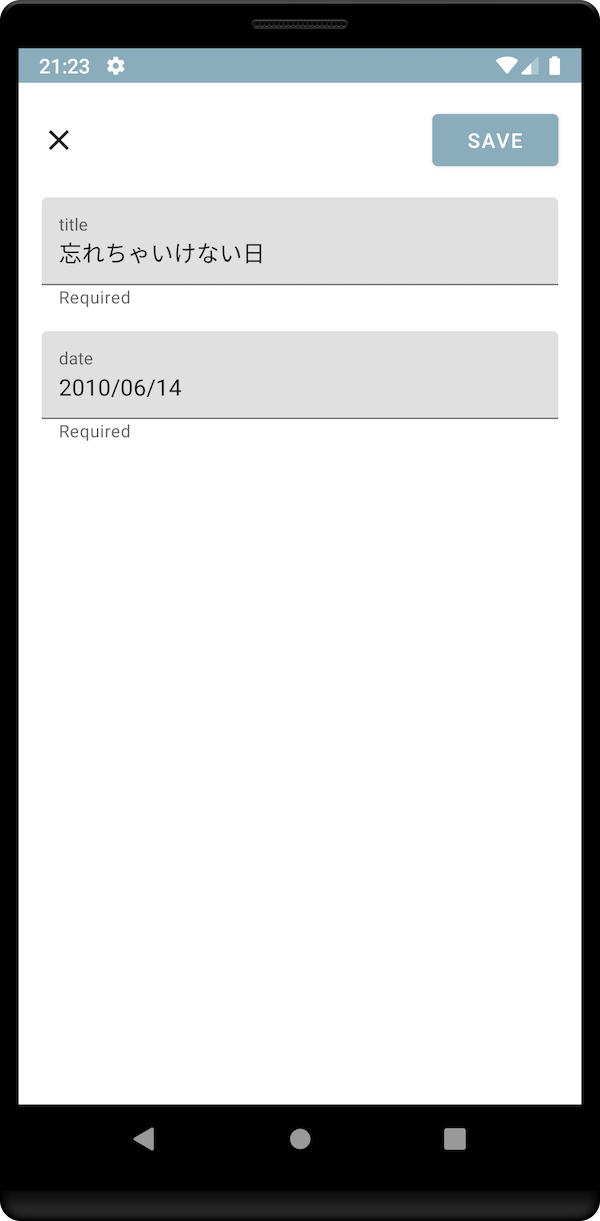
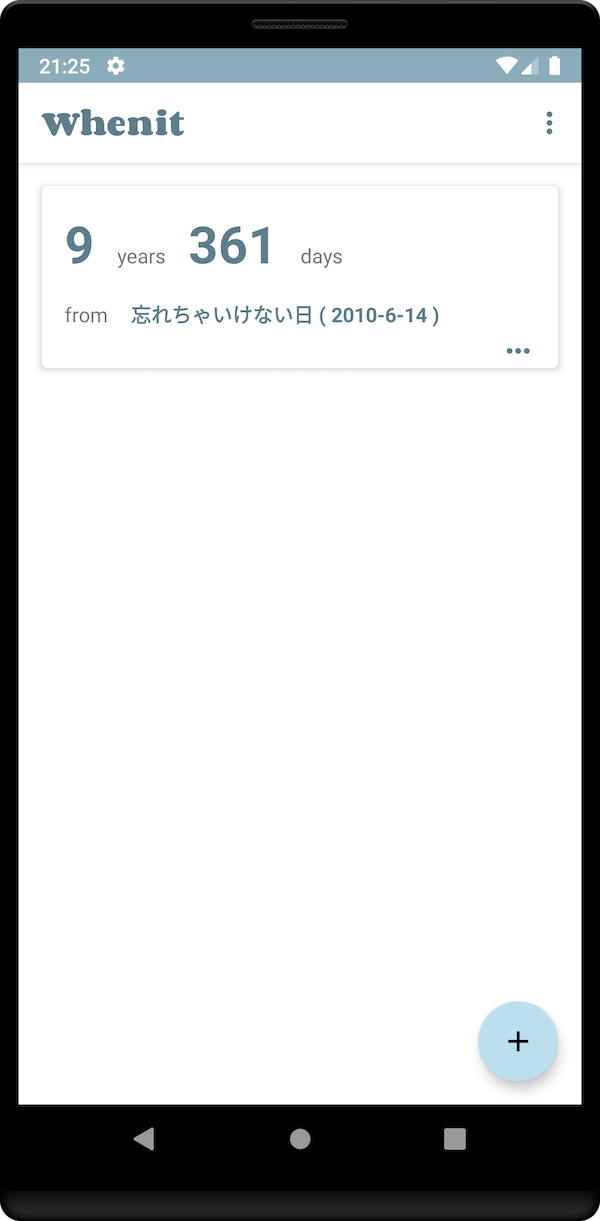
記念日を忘れないためのAndroidアプリをつくった
以前、記念日を忘れないためのWebアプリを作りました。
しかし、致命的な弱点がありました。それはオンラインじゃないと動かないということです。つまり、飛行機で上空にいるタイミングで「もう少しで結婚記念日だわね〜」みたいな会話になった時に、何年目だっけ!?というのをすぐに確認できません!!!
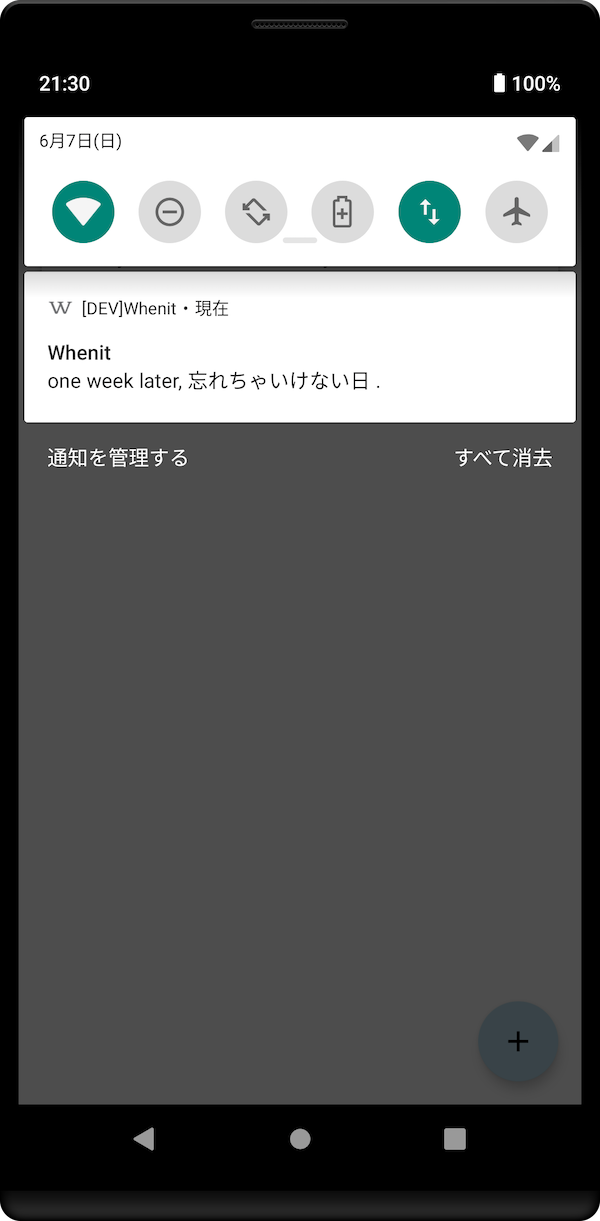
というわけでAndroidアプリとしてオフラインで動くように作りました。あと通知でリマインドする機能も追加。これでばっちりです。
開発メモ
という理由に加えて、2020年になってから久しぶりに仕事でもガッツリとAndroidアプリ開発に携わることにもなったので、練習がてら作り初めてみたのです。
久しぶりのAndroidアプリ開発は、以前と比べてとても快適になっていました。これまでにもいろいろなアーキテクチャやコンポーネントがありましたが、2020年時点では Jetpack というラベル付けで提供されるものを使うと良さそうです。
快適とはいえ学ぶことは多かったので、どんなことを調べたっけなというのをメモ。
Kotlin
プログラミング言語はJavaではなくKotlinになってる。Kotlin Bootcamp Courseというcodelabをやりつつ公式ドキュメントを参照するというのをやった。Kotlin イン・アクション という本も読んだけどKotlinのバージョンが古いので、こちらも公式ドキュメントを参照しながら。特にCoroutine周りは公式ドキュメントが読みながらコード書いてみるのが良い。
- Reference - Kotlin Programming Language
- codelab: Kotlin Bootcamp Course
- [asin:B076Q2L1M6:title]
- Coroutins Guide
Jetpack
Kotlinを使ったAndroidアプリ開発のcodelabをやった。Jetpackコンポーネントも使いつつなので良い。
Android KTXを使うといろいろ便利。以下をよく使う。
codelabが終わったらすぐに以下の記事を読んでおけばよかった。
Dagger
DIコンテナ。Android DevelopersにもDaggerのページがあるし、codelabも用意されているのでデファクトスタンダード感。これらのドキュメントのViewModelはJetpackのViewModelではないのでちょっと混乱した...
- Dependency injection in Android | Android デベロッパー | Android Developers
- codelab: Using Dagger in your Android app - Kotlin
Dagger単体ならまだしもAndroidと合わせて使うと難しい。この本読みながらいろいろ試行錯誤した。
DaggerのAndroid拡張はドキュメントや本を読んでもスッと入ってこない。SubComponentを良い感じに取り扱う方法は結局よく分からず。
テスト
テストはユニットテストをちょっとしか書けていない。ViewModelとLiveDataを使ったテストは難しい。。いろいろ読み漁った。
- codelab: Advanced Android in Kotlin 05.1: Testing Basics
- Android Architecture Componentとテスト2019年7月版 / Testing Android Architecture Components in 2019-07 - Speaker Deck
- Easy Coroutines in Android: viewModelScope - Android Developers - Medium
- kotlinx-coroutines-test
- LiveDataのUnitTest - Kenji Abe - Medium
しかもJUnit5を普通に使うだけだとうまくいかないのを解決できずJUnit4を使ってる。Androidのコンポーネントに依存しないテストはJUnit5で書くなどして、バージョン4と5が混在しても大丈夫。あんまり覚えてないけど、この記事ぱらぱらと読んだ気がする...。
モックライブラリのMockKは使いやすいと思った。
一覧画面
codelabには出てこないけどやりたかったこと。
スクロールするとUIにないデータを取りにいくという処理はpagingを使う。
スクロールに応じてToolbarやFloating Action Buttonを動かすにはCoodinateLayoutを使う。
UIの細かいところ
角丸にするのがよく分からなかったり...
リップル対応したり...
アイコン
こちらを使って W の1文字で...
ライセンス表記
使用しているライブラリのライセンス表示はこちらを使って。
開発中のデバッグ
このスライドがとても参考になった。
おしまい
Androidは自分のためのアプリをつくって日常で使えて良いですね!
GAE Go1.11 のdev_appserver.pyでホットリロードが効かないとき
GAE Go1.11 の dev_appserver.py でホットリロードが効かないなーというとき、dev_appserver.py実行時に以下のメッセージが出力されてました。最後の1行が出力されているとホットリロードが効きません。
$ dev_appserver.py dev.yaml INFO 2019-09-22 10:30:40,611 api_server.py:275] Starting API server at: http://localhost:51877 INFO 2019-09-22 10:30:40,613 instance_factory.py:170] Building with dependencies from GOPATH. INFO 2019-09-22 10:30:40,618 dispatcher.py:256] Starting module "sample" running at: http://localhost:8080 INFO 2019-09-22 10:30:40,621 admin_server.py:150] Starting admin server at: http://localhost:8000 WARNING 2019-09-22 10:30:40,621 devappserver2.py:373] No default module found. Ignoring. /Users/hoge/local/google-cloud-sdk/platform/google_appengine/google/appengine/tools/devappserver2/mtime_file_watcher.py:182: UserWarning: There are too many files in your application for changes in all of them to be monitored. You may have to restart the development server to see some changes to your files.
監視ファイル対象が多すぎるのが原因らしい。node_modulesとかホットリロードの対象にしなくて良いファイル/ディレクトリ除外して対応したいです。
結果
以下のように実行すればOKでした。
$ GO111MODULE=on dev_appserver.py dev.yaml --watcher_ignore_re ".*/node_modules/.*"
--watcher_ignore_reオプションで正規表現を使ってプロジェクト内で監視対象が除きたいものを指定できますGO111MODULE=onを明示的に指定してないとdev_appserver.pyでは$GOPATH/src配下のファイルたちも監視対象としてしまうようです(GO111MODULE=autoもダメ)
けど、公式ドキュメントを読むとGo1.11からはローカルで動かすときにdev_appserver.pyの話は出てこなく go run と書いてあるからホットリロードは別の方法を検討しすべきなのかなぁ。
結果に行き着くまでの流れ
--watcher_ignore_re
無視するオプションないかなぁと思って確認すると --watcher_ignore_re というオプションがあるようだ。
$ dev_appserver.py --help
...
--watcher_ignore_re WATCHER_IGNORE_RE
Regex string to specify files to be ignored by the
filewatcher. (default: None)
...
実行コマンドを以下のようにしてみた。
$ dev_appserver.py --watcher_ignore_re ".*/node_modules/.*" ... /Users/hoge/local/google-cloud-sdk/platform/google_appengine/google/appengine/tools/devappserver2/mtime_file_watcher.py:182: UserWarning: There are too many files in your application for changes in all of them to be monitored. You may have to restart the development server to see some changes to your files.
まだダメだ...。
GO111MODULE=on
なぜだろうと dev_appserver.py のコードを読み始める。Printデバッグしながら頑張る。
まず、dev_appserver.pyからは <gcloudをインストールしたディレクトリ>/platform/google_appengine/google/appengine/tools/devappserver2/devappserver.py を実行してる。
ここからはdevappserver.py と同じディレクトリのファイルを見ていく。
devappserver.py => dispatcher.py (Dispatcherをインスタンス化) => dispatcher.py (startメソッド)という流れで処理が行われる。
dispatcher.py
dispatcher.pyの252行目。このメッセージは見たことがある。dev_appserver.pyを実行した時に3行目に出力されていたログメッセージだ。
log_message = 'Starting module "%s" running at: http://%s' % (
module_configuration.module_name, _service.balanced_address)
その前の357行目。
module_instance = module_class(
この部分でGAEのmodule(現在はserviceと呼ばれる)を表すオブジェクトを生成しているようだ。Printデバッグしたところ module_class は module.AutoScalingModule だったのでコードを読み進める。
module.py
module.py の1251行目。 Module クラスを継承してる。
class AutoScalingModule(Module):
1309行目。 __init__ の中。
super(AutoScalingModule, self).__init__(**kwargs)
親クラスを見る。フィールドを初期化してるだけのコンストラクタだった。
dispatcher.pyに戻る。
_service = self._create_module(module_configuration, service_port,
ssl_port)
_service.start()
インスタンスを生成して start メソッドを呼んでるので AutScalingModuleの start を確認。
def start(self): """Start background management of the Module.""" self._balanced_module.start() self._port_registry.add(self.balanced_port, self, None) if self._ssl_port: self._port_registry.add(self._ssl_port, self, None) if self._watcher: self._watcher.start() self.report_start_metrics() self._instance_adjustment_thread.start()
self._balanced_module.start() を呼んでる。あと self._watcher.start() も呼んでる。
ファイルが多すぎるとメッセージを出力していたのは mtime_file_watcher.py だった。 self._watcher は怪しい。self._watcher はなんだったか。
再びmodule.pyへ。
module.pyの600行目。ここで self._watcher をセットしてる。
if self._automatic_restarts: self._watcher = file_watcher.get_file_watcher( [self._module_configuration.application_root] + self._instance_factory.get_restart_directories(), self._use_mtime_file_watcher) if hasattr(self._watcher, 'set_watcher_ignore_re'): self._watcher.set_watcher_ignore_re(self._watcher_ignore_re) if hasattr(self._watcher, 'set_skip_files_re'): self._watcher.set_skip_files_re(self._module_configuration.skip_files) else: self._watcher = None
file_watcher.get_file_watcher( ここだ!
file_watcher.py
file_watcher.pyの151行目
def get_file_watcher(directories, use_mtime_file_watcher):
この directories をprintしてみると
['/Users/hoge/work/sample-app', '/Users/hoge/go/src']
むむ、思ってるのと違うディレクトリが混ざっている。 /Users/hoge/go/src ...。これは GOPATH/src だな。これが監視対象ならそりゃ監視対象となるファイル数が多くなってしまう。どこで紛れ込んだのだろう。
またまたmodule.pyへ
さっきのmodule.pyに戻る。 get_file_watcher の direcotories 引数を指定している部分を見てみる。
[self._module_configuration.application_root] + self._instance_factory.get_restart_directories()
1つ目のリストが '/Users/hoge/work/sample-app' だから、おそらく self._instance_factory.get_restart_directories() これが怪しい。これが '/Users/hoge/go/src' を生成してるのではないか。
self._instance_factory は何か。 get_file_watcher を呼び出し箇所のすぐ上、597行目。
self._instance_factory = self._create_instance_factory(
self._module_configuration)
_create_instance_factory をチェック。193行目。
def _create_instance_factory(self, module_configuration):
追っていくと、runtime_factories.goの FACTORIES という辞書でruntimeごとに定義されている!
FACTORIES = {
'go': go_factory.GoRuntimeInstanceFactory,
'go111': go_factory.GoRuntimeInstanceFactory,
'php55': php_factory.PHPRuntimeInstanceFactory,
'php72': php_factory.PHPRuntimeInstanceFactory,
'python': python_factory.PythonRuntimeInstanceFactory,
'python37': python_factory.PythonRuntimeInstanceFactory,
'python27': python_factory.PythonRuntimeInstanceFactory,
'python-compat': python_factory.PythonRuntimeInstanceFactory,
'custom': custom_factory.CustomRuntimeInstanceFactory,
}
go/instance_factory.py
今回のruntimeはgo111なので、 go_factory.GoRuntimeInstanceFactory が _instance_factory の実体だ。知りたかったのは self._instance_factory.get_restart_directories() なので確認。
...devappserver2/go/instance_factory.pyに get_restart_directories() を発見。
# Go < 1.11 should always watch GOPATH # Go == 1.11 should only watch GOPATH if GO111MODULE != on # Go > 1.11 should only watch go.mod dir go_mod_dir = self._find_go_mod_dir( self._module_configuration.application_root) if os.getenv('GO111MODULE', '').lower() == 'on' and go_mod_dir: logging.info('Building with dependencies from go.mod.') return [go_mod_dir] logging.info('Building with dependencies from GOPATH.')
あー、この 'Building with dependencies from GOPATH.' というログもdev_appserver.pyを起動する時に見るやつ。
ん、ということはGO111MODULE=autoに対応してないのでは?とよく読むとコメントに書いてるー!
# Go == 1.11 should only watch GOPATH if GO111MODULE != on
ということで、以下のようなコマンドでdev_appserver.pyを実行する。
$ GO111MODULE=on dev_appserver.py local.yaml --watcher_ignore_re ".*/node_modules/.*" INFO 2019-09-22 11:08:14,068 api_server.py:275] Starting API server at: http://localhost:52385 INFO 2019-09-22 11:08:14,070 instance_factory.py:168] Building with dependencies from go.mod. INFO 2019-09-22 11:08:14,075 dispatcher.py:256] Starting module "sample" running at: http://localhost:8080 INFO 2019-09-22 11:08:14,079 admin_server.py:150] Starting admin server at: http://localhost:8000 WARNING 2019-09-22 11:08:14,079 devappserver2.py:373] No default module found. Ignoring.
キター!ホットリロードもできました!
おしまい
ちなみに、GO111MODULE=on だけでもいけるんじゃないかと思って試しましたが、今回は --watcher_ignore_re ".*/node_modules/.*" も必要でした。
SQLアンチパターン・ジェイウォークのクエリをシェルでやる
SQLアンチパターンという本があります。 その本の1章がジェイウォーク(信号無視)。ジェイウォークで紹介されているようなデータがtsvファイルとして手元にある場合に、SQLではなくシェルでなんとかするお話です。

- 作者: Bill Karwin,和田卓人,和田省二,児島修
- 出版社/メーカー: オライリージャパン
- 発売日: 2013/01/26
- メディア: 大型本
- 購入: 9人 クリック: 698回
- この商品を含むブログ (46件) を見る
試しに使ったMySQLのバージョンは5.7です。
ジェイウォーク
製品テーブルとアカウントテーブルがあり、製品ごとに複数人の担当者(アカウント)がいる、とする
CREATE TABLE `accounts` ( `account_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `account_name` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`account_id`), UNIQUE KEY `account_id` (`account_id`) ) CREATE TABLE `products` ( `product_id` bigint(20) unsigned NOT NULL AUTO_INCREMENT, `product_name` varchar(1000) COLLATE utf8mb4_bin DEFAULT NULL, `account_id` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`product_id`), UNIQUE KEY `product_id` (`product_id`) )
mysql> SELECT * FROM products; +------------+---------------------+------------+ | product_id | product_name | account_id | +------------+---------------------+------------+ | 1 | Visual TurboBuilder | 12,34 | | 2 | hoge fuga | 555,666 | +------------+---------------------+------------+ mysql> SELECT * FROM accounts; +------------+--------------+ | account_id | account_name | +------------+--------------+ | 12 | taro | | 34 | hanako | | 555 | goro | +------------+--------------+
製品テーブルのaccount_idカラムに、複数のアカウントIDをカンマ区切りの文字列として保持するアンチパターン。
tsvファイル
同じようなtsvファイルがあるとする。
$ cat products.tsv product_id product_name account_id 1 Visual TurboBuilder 12,34 2 hoge fuga 555,666,777 $ cat accounts.tsv account_id account_name 12 taro 34 hanako 555 goro
SQL vs シェル
特定のアカウントに関連する製品の検索
account_id=12に関連するproductsを検索する。
SQLアンチパターンで紹介されているSQLは以下。正規表現を使った WHERE 句の指定がなかなか強烈...。
SELECT * FROM products; +------------+---------------------+-------------+ | product_id | product_name | account_id | +------------+---------------------+-------------+ | 1 | Visual TurboBuilder | 12,34 | | 2 | hoge fuga | 555,666,777 | +------------+---------------------+-------------+
SELECT * FROM products WHERE account_id REGEXP '[[:<:]]12[[:>:]]'; +------------+---------------------+------------+ | product_id | product_name | account_id | +------------+---------------------+------------+ | 1 | Visual TurboBuilder | 12,34 | +------------+---------------------+------------+
対して、シェルでやってみる。 NR で行番号を取得してヘッダー行かそれ以外の行かで分岐、ヘッダー行以外の場合は $3 (3カラム目の値)と正規表現を使って行を絞り込む。
$ cat products.tsv product_id product_name account_id 1 Visual TurboBuilder 12,34 2 hoge fuga 555,666,777
$ cat products.tsv | awk -F '\t' '{
> if (NR == 1) { print } #ヘッダー行を出力
> else if ($3 ~ /12/) { print } #ヘッダー行以外は account_id=12 で絞り込み
> }'
product_id product_name account_id
1 Visual TurboBuilder 12,34
ヘッダー行の出力をなんとかして if をなくしたいなぁ、いい方法ないだろうか?
特定の製品に関連するアカウントの検索
product_id=1に関連するアカウント情報の一覧を取得する。
SQLアンチパターンで紹介されているSQLは以下。
SELECT * FROM products; +------------+---------------------+-------------+ | product_id | product_name | account_id | +------------+---------------------+-------------+ | 1 | Visual TurboBuilder | 12,34 | | 2 | hoge fuga | 555,666,777 | +------------+---------------------+-------------+ SELECT * FROM accounts; +------------+--------------+ | account_id | account_name | +------------+--------------+ | 12 | taro | | 34 | hanako | | 555 | goro | +------------+--------------+
SELECT * FROM products AS p INNER JOIN accounts AS a ON p.account_id REGEXP CONCAT('[[:<:]]', a.account_id, '[[:>:]]') WHERE p.product_id = 1; +------------+---------------------+------------+------------+--------------+ | product_id | product_name | account_id | account_id | account_name | +------------+---------------------+------------+------------+--------------+ | 1 | Visual TurboBuilder | 12,34 | 12 | taro | | 1 | Visual TurboBuilder | 12,34 | 34 | hanako | +------------+---------------------+------------+------------+--------------+
シェルでやってみる。
$ cat products.tsv product_id product_name account_id 1 Visual TurboBuilder 12,34 2 hoge fuga 555,666,777 $ cat accounts.tsv account_id account_name 12 taro 34 hanako 555 goro
ヘッダー行の取り扱いはさっきと同じ。 split を使ってカンマ区切りの文字列を配列にセット、配列に対するループ内で print することで、account_id毎の行に展開する。結果は、tmp_product.tsvというファイルに書き込んでおく。
$ cat products.tsv | awk -F '\t' '{
> if (NR == 1) { print } #ヘッダー行を出力
> else if ($1 == 1) { #ヘッダー行以外は product_id=1 で絞り込み
> split($3, arr, ","); #splitでカンマで分割
> for (i in arr) {
> print $1 "\t" $2 "\t" arr[i] #複数行に展開
> }
> }
> }' > tmp_product.tsv
$ cat tmp_product.tsv
product_id product_name account_id
1 Visual TurboBuilder 12
1 Visual TurboBuilder 34
作成したtmp_product.tsvとaccounts.tsvとを、account_id列でjoinする。タブ文字区切りにしたいので -t オプションを使うが "\t" という指定をしてもタブ文字として扱ってくれないので、bashの ${string}の記法を使って指定する(この記法は何か呼び名はあるのかな?)。
$ join --header -t $'\t' -1 3 -2 1 tmp_product.tsv accounts.tsv account_id product_id product_name account_name 12 1 Visual TurboBuilder taro 34 1 Visual TurboBuilder hanako
できた!
ワンライナーで書きたい場合は、bashだとプロセス置換を使ってjoinコマンドで読む。
$ join --header -t $'\t' -1 3 -2 1 <(cat products.tsv | awk -F '\t' '{ if (NR == 1) { print } else if ($1 == 1) { split($3, arr, ","); for (i in arr) { print $1 "\t" $2 "\t" arr[i] }}}') accounts.tsv
account_id product_id product_name account_name
12 1 Visual TurboBuilder taro
34 1 Visual TurboBuilder hanako
集約クエリ
product毎に関連するaccountの数を取得する。
SQLアンチパターンで紹介されてるクエリは以下。文字列長からカンマ以外の文字列長を引くことでカンマの数を取得して +1 する。これもなかなか強烈。
SELECT product_id, LENGTH(account_id) - LENGTH(REPLACE(account_id, ',', '')) + 1 AS contracts_per_product FROM products; +------------+-----------------------+ | product_id | contracts_per_product | +------------+-----------------------+ | 1 | 2 | | 2 | 3 | +------------+-----------------------+
これはシェルなら簡単。awkのsplitが配列の要素の数を返してくれるので、それを出力すればOK!
$ cat products.tsv | awk -F '\t' '
> BEGIN { print "product_id" "\t" "contracts_per_product"} #BEGINでヘッダー行を出力する
> NR > 1 {
> n = split($3, arr, ",");
> print $1 "\t" n
> }'
product_id contracts_per_product
1 2
2 3
おしまい
シェルはおもしろいですね!